
Acredito que muitos dos leitores deste blog em algum momento de suas carreiras já devam ter passado por uma situação de falha de discos em um servidor.
Apesar de ter minha carreira focada para o mundo de redes muitas vezes acabo me aventurando em outras áreas, compartilhando um pouco da experiência adquirida vamos a um passo-a-passo de como recuperar um array de discos em RAID um com um disco defeituoso.
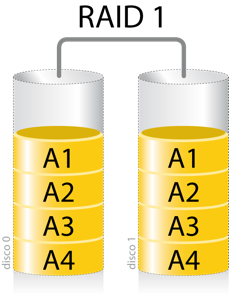
Supondo que você tenha um cenário parecido com o ilustrado na imagem deste post (dois discos físicos com quatro partições) o output do comando cat /proc/mdstat em uma operação normal deveria ser algo parecido com isso:
brainServer01:~# cat /proc/mdstat
Personalities : [raid1] md0 : active raid1 sda1[0] sdb1[1] 244186 blocks [2/2] [UU]
md1 : active raid1 sda2[0] sdb2[1] 34522688 blocks [2/2] [UU]
md2 : active raid1 sda3[0] sdb3[1] 1573888 blocks [2/2] [UU]
md2 : active raid1 sda4[0] sdb4[1] 128384 blocks [2/2] [UU]
unused devices: <none>
Mas no caso de falha de um dos discos (detectado nos logs (/var/log/message ou /var/log/syslog) poderia ficar assim:

brainServer01:~# cat /proc/mdstat
Personalities : [raid1] md0 : active raid1 sda1[0] sdb1[1] 244186 blocks [2/2] [UU]md1 : active raid1 sda2[0] sdb2[1] 34522688 blocks [2/1] [U_]
md2 : active raid1 sda3[0] sdb3[1] 1573888 blocks [2/1] [U_]
md2 : active raid1 sda4[0] sdb4[1] 128384 blocks [2/2] [UU]
unused devices: <none>
Neste caso o melhor a se fazer é a substituição do disco, primeiramente marcando todas as partições do disco defeituoso como fail:
brainServer01:~# mdadm –manage /dev/md0 –fail /dev/sdb1
(repita a operação para as demais partições)
Ao final teremos ao do tipo (letra (F) na frente do disco marcado como fail):
brainServer01:~# cat /proc/mdstat
Personalities : [raid1] md0 : active raid1 sda1[0] sdb1[1](F)
244186 blocks [2/2] [U_]md1 : active raid1 sda2[0] sdb2[1](F)
34522688 blocks [2/1] [U_]md2 : active raid1 sda3[0] sdb3[1](F)
1573888 blocks [2/1] [U_]md2 : active raid1 sda4[0] sdb4[1](F)
128384 blocks [2/2] [U_]
Remova as partições do array:
brainServer01:~# mdadm –manage /dev/md0 –remove /dev/sdb1
mdadm: hot removed /dev/sdb1
(repita a operação para as demais partições)
As partições do disco defeituoso sumirão do array:
brainServer01:~# cat /proc/mdstat
Personalities : [raid1] md0 : active raid1 sda1[0] 244186 blocks [2/2] [U_]md1 : active raid1 sda2[0] 34522688 blocks [2/1] [U_]
md2 : active raid1 sda3[0] 1573888 blocks [2/1] [U_]
md2 : active raid1 sda4[0] 128384 blocks [2/2] [U_]
Desligue o servidor com shutdown -h now e retire o disco defeituoso substituindo-o por um de igual tamanho. Quando ligar a máquina novamente particione o novo disco exatamente como o disco de produção utilizando o fdisk. Depois disso mapeie as partiições ao array:
brainServer01:~# mdadm –manage /dev/md0 –add /dev/sdb1
mdadm: re-added /dev/sdb1
(repita a operação para as demais partições)
Você pode acompanhar o re-sync dos discos, que pode levar algum tempo dependendo do tamanho, velocidade do disco etc…
brainServer01:~# cat /proc/mdstat
Personalities : [raid1] md0 : active raid1 sda1[0] sdb1[1] 244186 blocks [2/2] [UU]md1 : active raid1 sda2[0] sdb2[1] 34522688 blocks [2/2] [UU]
md2 : active raid1 sda3[0] sdb3[1] 1573888 blocks [2/2] [UU]
md2 : active raid1 sda4[0] sdb4[1] 128384 blocks [2/1] [U_] [==>……………….] recovery = 12.2% (15725/128384) finish=1.9min speed=19651K/sec
unused devices: <none>
Quando o re-sync terminar o output do comando deve mostar uma operação normal e seu sistema deve ter voltado ao normal … 🙂


Interessante!!!
Seu site é realmente muito bom, parabéns pelo trabalho!