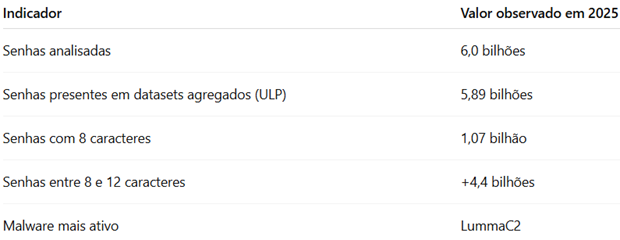
No dia 19 de setembro de 2025, clientes que utilizam Cisco Umbrella, Secure Access e Secure Connect enfrentaram instabilidades que afetaram serviços essenciais de DNS, Secure Web Gateway (SWG), Reserved IP e túneis de rede.
O problema, apesar de controlado em poucas horas, gerou impacto significativo para diversas organizações que dependem da plataforma para operações críticas.

Neste artigo, vamos detalhar o incidente, as causas identificadas e as medidas corretivas anunciadas pela Cisco.
Linha do tempo do incidente
O evento começou em 19 de setembro de 2025, às 19h38 UTC, quando falhas começaram a ser registradas nos serviços de DNS. Poucos minutos depois, às 19h45, parte dos resolvedores conseguiu se recuperar automaticamente.
Entre 20h24 e 21h00, a equipe de engenharia da Cisco identificou a causa raiz, desenhou e testou uma solução de contorno. Às 21h15, a maior parte dos serviços já estava normalizada, encerrando o período de maior impacto.
Nos dias seguintes, a empresa conduziu uma implementação gradual da correção definitiva: no dia 21 de setembro, todos os servidores SWG e DNS já estavam com o ajuste permanente aplicado.
Causa raiz: falha em otimização de regras
A instabilidade não foi causada por ataque externo, mas sim por um defeito no software de geração e processamento de políticas.
Segundo o relatório, a Cisco havia introduzido uma otimização para acelerar o processamento de listas extensas de objetos de rede. Contudo, essa alteração acabou gerando instabilidade, resultando em falhas nas aplicações de DNS e SWG.
Essa falha se manifestou em diferentes formas:
-
Resolução de DNS lenta ou falha
-
Problemas de enforcement em gateways SWG
-
Inconsistências no uso de IPs reservados
-
Timeouts em túneis de rede
Portanto, o impacto variou conforme o tipo de serviço, o horário e a região do data center acessado pelos clientes.
Impacto global e repercussão
O período mais crítico durou menos de duas horas. Ainda assim, o efeito foi percebido mundialmente, atingindo clientes de diferentes portes e setores.
No Brasil, provedores de serviços e empresas que utilizam Cisco Umbrella para proteção de tráfego DNS relataram instabilidades na resolução de nomes, especialmente durante a janela inicial do problema.
A própria Cisco destaca que o alerta inicial partiu tanto de seus sistemas de monitoramento interno quanto de clientes que entraram em contato com o suporte quase imediatamente após a falha.
Ações corretivas e próximos passos
A Cisco informou que a falha foi corrigida rapidamente com um workaround e que a correção permanente já está em produção. Além disso, foram anunciadas medidas adicionais para evitar reincidências:
-
Correção do defeito de código responsável pela falha (já concluída).
-
Ampliação dos testes internos, especialmente voltados para cenários de borda e listas de objetos de rede muito extensas (em andamento).
-
A empresa também afirmou que novas ações poderão ser adicionadas conforme a análise retrospectiva avance.
Conclusão
Embora o incidente tenha durado menos de duas horas em seu pico, o impacto foi expressivo, e acabou com o 100% de disponibilidade histórica que o serviço Umbrella tinha até então. E este evento reforça a importância de processos rigorosos de teste em ambientes complexos e distribuídos como os de segurança em nuvem.
Para administradores e equipes de segurança, o caso serve como alerta: ter redundância, monitoramento contínuo e planos de contingência é essencial para lidar com falhas inevitáveis em serviços críticos de segurança e rede.